Doris(原百度Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在2017年开源,2018年8月进入Apache孵化器。Apache Doris被数百家企业应用在生产系统,包含美团、京东、小米、字节、华为、腾讯等公司。
2022年1月由 Apache Doris 创始团队和百度智能云创始团队创立的飞轮科技(SelectDB),总部位于北京,并在西安、成都、深圳、广州、杭州、上海、新加坡、美国硅谷设有研发中心和分公司,公司目前近200人。连续完成3轮融资,累计融资额近10亿,投资方为红杉中国、IDG资本等头部VC。
下面将从下面2个部分介绍Apache Doris(实时的分析型数据)
Doris定位:即 Doris所要面临的业务场景及解决的问题;
产品定位: MPP 架构的关系型分析数据库; PB 级别大数据集,秒级/毫秒级查询; 主要用于多维分析和报表查询; 2018年进入 Apache 孵化器;
数据分析中的定位:
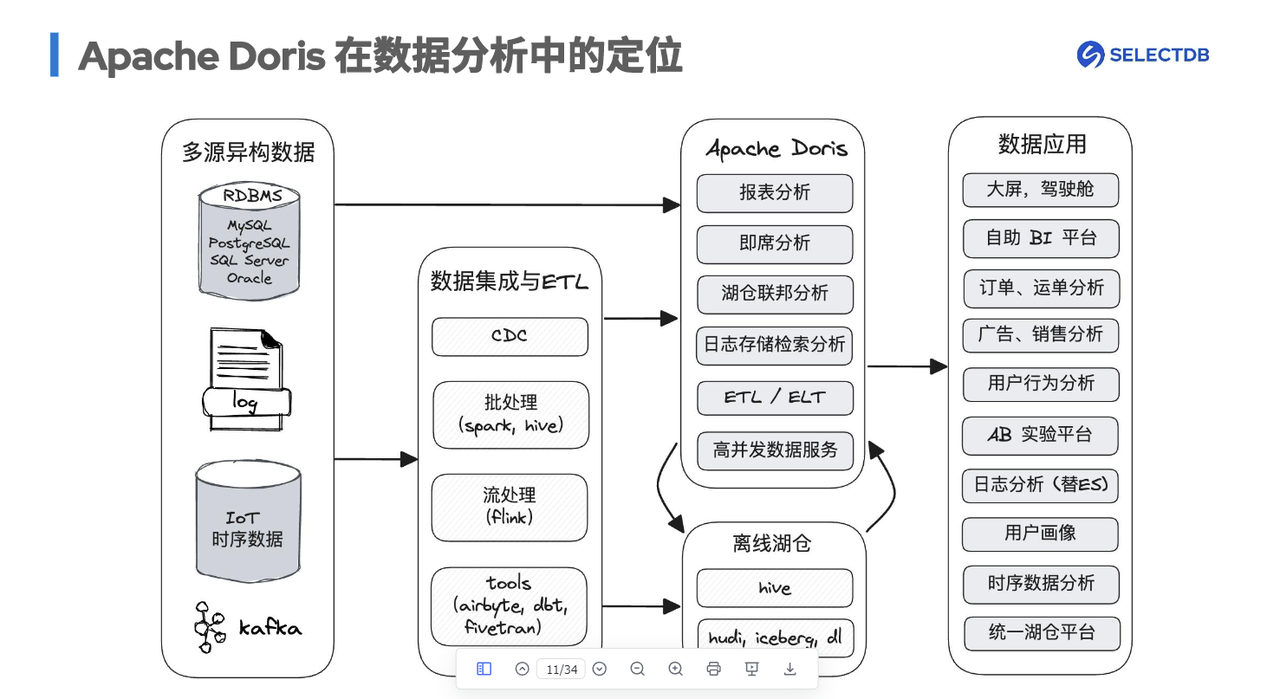
Doris关键技术
Doris整体架构,如下图:
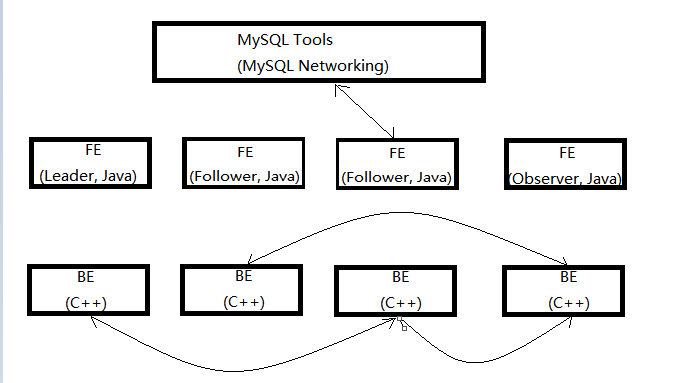 Doris主要分为FE和BE两个组件,FE主要负责查询的编译,分发和元数据管理(基于内存,类似HDFSNN);BE主要负责查询的执行和存储系统。
Doris主要分为FE和BE两个组件,FE主要负责查询的编译,分发和元数据管理(基于内存,类似HDFSNN);BE主要负责查询的执行和存储系统。
如上图,Doris的架构很简洁,只设FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。
1、以数据存储的角度观之,FE存储、维护集群元数据;BE存储物理数据。 2、以查询处理的角度观之, FE节点接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果;BE节点依据FE生成的物理计划,分布式地执行查询。 3、FE主要有有三个角色,一个是leader,一个是follower,还有一个observer。leader跟follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。 4、右边observer只是用来扩展查询节点,就是说如果在发现集群日压力非常大的情况下,需要去扩展整个查询的能力,那么可以加observer的节点。observer不参与任何的写入,只参与读取。 5、数据的可靠性由BE保证,BE会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
Doris数据组织:
Doris数据组织主要体现在其独特的数据结构和处理机制上。Doris是一个开源的分布式计算框架,旨在解决大规模数据处理和分析的问题。以下是关于Doris数据组织的一些关键方面:
分布式架构:Doris采用分布式架构,其中包括多个节点组成的集群。每个节点都可以存储和处理数据,并且节点之间可以进行数据的分片和负载均衡。这种架构使得Doris能够处理海量数据,并提供了高可用性。
列式存储:Doris使用列式存储引擎,这意味着数据按列存储在磁盘上,而不是按行存储。这种存储方式使得Doris能够高效地执行聚合操作和列裁剪,从而提高查询性能。
数据表模型:在Doris中,数据被组织成数据库和表的层次结构。每个列都有一个名称和数据类型,这种结构化的组织方式使得数据管理和查询变得更加简单和高效。
数据副本和容错:为了保证数据的可靠性和容错能力,Doris使用数据副本机制。每个数据分片都有多个副本存储在不同的节点上,当某个节点发生故障时,系统可以自动切换到其他副本,保证数据的可用性。
通过以上这些机制,Doris数据组织实现了高效的数据处理、查询和分析能力,为各种业务场景提供了强大的数据支持。无论是游戏数据统计、广告数据分析、物流数据管理,还是金融风控系统和在线广播系统,Doris都能有效地存储、管理和分析大量数据,为企业决策提供有力支持。
向量化执行: 向量化执行引擎的初衷是为了替换Apache Doris当前基于行式内存格式和传统火山模型的SQL执行引擎。这种替换的目的是为了充分释放现代CPU的计算能力,突破SQL执行引擎在性能上的限制,从而发挥出极致的性能表现。
那么,向量化执行引擎是如何实现这一点的?
它重新设计了在列式存储系统的SQL执行引擎。在内存的数据结构方面,向量化执行引擎使用Column来替换Tuple,这提高了计算时的Cache亲和度、分支预测以及预取内存的友好度。换句话说,这种数据结构的变化使得CPU能够更有效地从内存中读取数据并进行计算,从而提高了执行效率。
向量化执行引擎采用分批进行类型判断的方式。在本批次中,所有行都使用在类型判断时确定的类型,这样可以将每一行类型判断的虚函数开销分摊到批量级别,进一步提高了执行效率。
向量化执行引擎还充分利用了现代CPU的特性,特别是SIMD(Single Instruction Multiple Data)指令集。SIMD指令集允许CPU将单个指令应用于多个数据,这大大提高了计算效率。例如,具有128位寄存器的CPU可以一次保存4个32位数并进行一次计算,这比一次执行一条指令快4倍。
向量化执行引擎的数据结构还包括列式存储、行式存储和位图存储等。列式存储将同一列的数据存储在一起,这有助于提高数据压缩和查询性能。行式存储则将一行数据存储在一起,这更适用于写入操作。而位图存储则是将数据按照二进制位进行存储,这可以高效地处理数据过滤和聚合计算。
以上是关于实时的分析型数据库(Apache Doris)部分知识点,如果有兴趣可以来我们的论坛一起探讨,点击https://ask.selectdb.com/。
