索引
索引用于帮助快速过滤或查找数据。目前主要支持两类索引:
- 内建的智能索引,包括ZoneMap索引和前缀索引。
- 用户创建的二级索引,包括 BloomFilter 索引和Bitmap倒排索引。
ZoneMap索引
其中 ZoneMap 索引是在列存格式上,对每一列自动维护的索引信息,包括 Min/Max,Null 值个数等等。这种索引对用户透明。
前缀索引
SelectDB的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
在 Aggregate、Unique 和 Duplicate 三种表引擎中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQUE KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。
而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
示例
我们将一行数据的前 36 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。我们举例说明:
-
以下表结构的前缀索引为 user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。
ColumnName Type user_id BIGINT age INT message VARCHAR(100) max_dwell_time DATETIME min_dwell_time DATETIME -
以下表结构的前缀索引为 user_name(20 Bytes)。即使没有达到 36 个字节,因为遇到 VARCHAR,所以直接截断,不再往后继续。
ColumnName Type user_name VARCHAR(20) age INT message VARCHAR(100) max_dwell_time DATETIME min_dwell_time DATETIME
当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
SELECT * FROM table WHERE user_id=1829239 and age=20;该查询的效率会远高于如下查询:
SELECT * FROM table WHERE age=20;所以在建表时,正确的选择列顺序,能够极大地提高查询效率。
通过 Rollup 来调整前缀索引
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。
BloomFilter索引
BloomFilter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合,BloomFilter有以下特点:
- 空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中。
- 对于一个元素检测是否存在的调用,BloomFilter会告诉调用者两个结果之一:可能存在或者一定不存在。
- 缺点是存在误判,告诉你可能存在,不一定真实存在。
布隆过滤器实际上是由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为1。
下图所示出一个 m=18, k=3 (m是该Bit数组的大小,k是Hash函数的个数)的Bloom Filter示例。集合中的 x、y、z 三个元素通过 3 个不同的哈希函数散列到位数组中。当查询元素w时,通过Hash函数计算之后因为有一个比特为0,因此w不在该集合中。
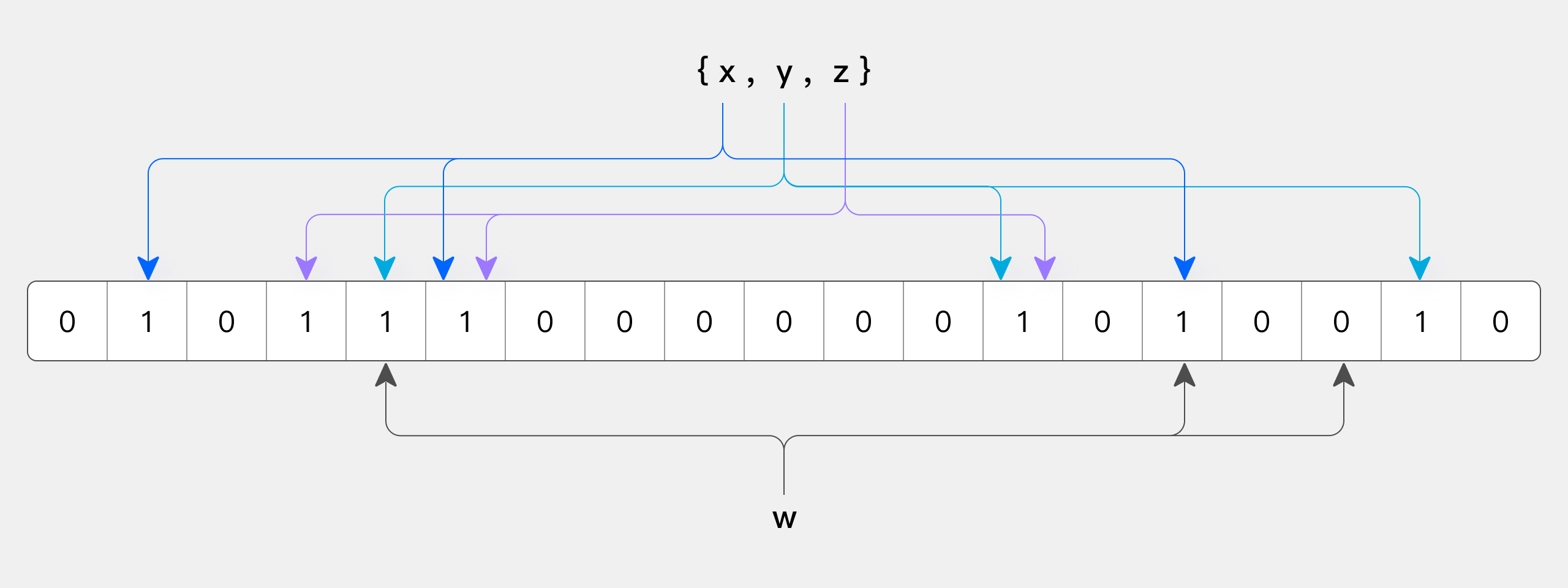
那么怎么判断某个元素是否在集合中呢?同样是这个元素经过哈希函数计算后得到所有的偏移位置,若这些位置全都为1,则判断这个元素在这个集合中,若有一个不为1,则判断这个元素不在这个集合中。
创建BloomFilter索引
BloomFilter本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回false,则一定不在这个集合内。而如果范围true,则有可能在这个集合内。
BloomFilter索引也是以Block为粒度创建的。每个Block中,指定列的值作为一个集合生成一个BloomFilter索引条目,用于在查询是快速过滤不满足条件的数据。
SelectDB的BloomFilter索引可以通过建表的时候指定,或者通过表的ALTER操作来完成。
BloomFilter索引的创建是通过在建表语句的PROPERTIES里加上"bloom_filter_columns"="k1,k2,k3",这个属性,k1,k2,k3是你要创建的BloomFilter索引的Key列名称,例如下面我们对表里的saler_id,category_id创建了BloomFilter索引。
CREATE TABLE IF NOT EXISTS sale_detail_bloom (
sale_date date NOT NULL COMMENT "销售时间",
customer_id int NOT NULL COMMENT "客户编号",
saler_id int NOT NULL COMMENT "销售员",
sku_id int NOT NULL COMMENT "商品编号",
category_id int NOT NULL COMMENT "商品分类",
sale_count int NOT NULL COMMENT "销售数量",
sale_price DECIMAL(12,2) NOT NULL COMMENT "单价",
sale_amt DECIMAL(20,2) COMMENT "销售总金额"
)
Duplicate KEY(sale_date, customer_id,saler_id,sku_id,category_id)
PROPERTIES (
"bloom_filter_columns"="saler_id,category_id",
);查看BloomFilter索引
查看我们在表上建立的BloomFilter索引是使用:
SHOW CREATE TABLE <table_name>;删除BloomFilter索引
删除索引即为将索引列从bloom_filter_columns属性中移除:
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "");修改BloomFilter索引
修改索引即为修改表的bloom_filter_columns属性:
ALTER TABLE <db.table_name> SET ("bloom_filter_columns" = "k1,k3");BloomFilter使用场景
满足以下几个条件时可以考虑对某列建立Bloom Filter 索引:
- 首先BloomFilter适用于非前缀过滤。
- 查询会根据该列高频过滤,而且查询条件大多是 in 和 = 过滤。
- 不同于Bitmap, BloomFilter适用于高基数列。比如UserID。因为如果创建在低基数的列上,比如 “性别” 列,则每个Block几乎都会包含所有取值,导致BloomFilter索引失去意义。
BloomFilter使用注意事项
- 不支持对Tinyint、Float、Double 类型的列建Bloom Filter索引。
- Bloom Filter索引只对 in 和 = 过滤查询有加速效果。
- 如果要查看某个查询是否命中了Bloom Filter索引,可以通过查询的Profile信息查看。
Bitmap 索引
bitmap index,位图索引,是一种快速数据结构,能够加快查询速度。这里主要介绍如何创建 index 作业,以及创建 index 的一些注意事项和常见问题。
创建索引
比如在table1上为siteid列创建bitmap 索引
CREATE INDEX [IF NOT EXISTS] index_name ON table1 (siteid) USING BITMAP;查看索引
展示指定 table_name 的下索引
SHOW INDEX FROM example_db.table_name;删除索引
删除指定 table_name 的下索引
DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name;注意事项
- bitmap 索引仅在单列上创建。
- bitmap 索引能够应用在
Duplicate、Uniq数据模型的所有列和Aggregate模型的key列上。 - bitmap 索引支持的数据类型如下:
TINYINTSMALLINTINTBIGINTCHARVARCHARDATEDATETIMELARGEINTDECIMALBOOL