Kafka SelectDB Connector 介绍
Kafka Connect 是一款可扩展、可靠的在 Apache Kafka 和其他系统之间进行数据传输的工具。 可以定义 Connectors 来将大量数据迁入迁出 Kafka。Kafka Connect 通过运行在 Kafka Connect 集群中,支持从 Kafka Topic 中读取数据,并将数据写入 SelectDB Cloud 表中。
SelectDB Cloud 提供了 Sink Connector 插件,可以将 Kafka Topic 中的 JSON 数据保存到 SelectDB Cloud 数据库中。
基础架构
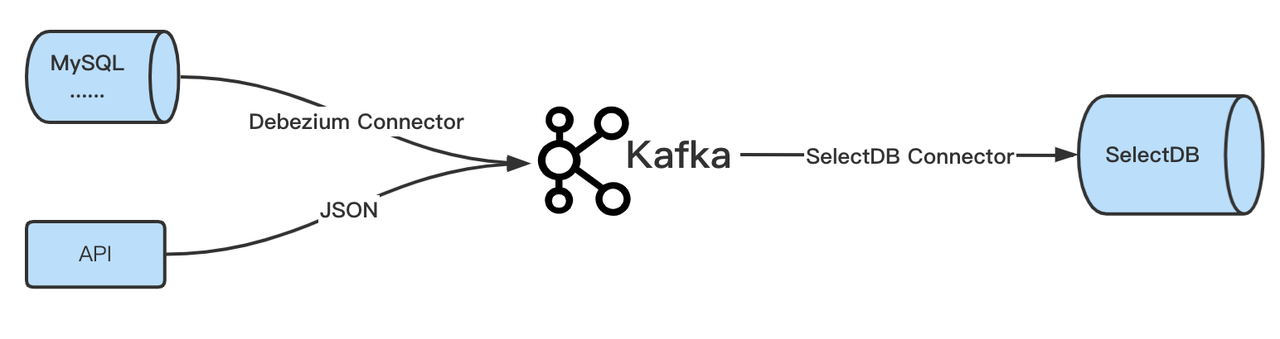
在业务场景中,通常会通过 Debezium Connector 将数据库的变更数据实时写入 Kafka;或者调用API往 Kafka 中推送 JSON 格式数据,使用SelectDB Connector即可将这些数据同步到 SelectDB Cloud 中。
工作原理
Kafka Connector 通过以下过程订阅 Kafka Topic 的数据,并将数据 sink 到 SelectDB Cloud 中。
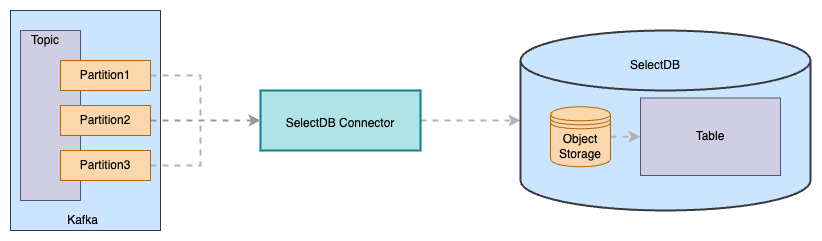
- SelectDB Connector 通过内部的 task 一对一或一对多的消费对应 topic partition 中的数据。当达到阈值(时间或内存或消息数量)时,Connector 会将该批次的 records 生成一个临时文件,并上传至 SelectDB Cloud 的对象储存中。
- 当临时文件数达到 50 个或 Connector 向 Kafka 集群预提交已成功消费的 offset 时(默认 10s ),将对象存储中的临时文件,通过 Copy-Into 操作导入至对应的 table 中。
Exactly-Once
Exactly-Once 语义是指即使在机器或应用出现故障的情况下,也不会重复处理数据或者丢失数据。SelectDB-Kafka-Connector 通过 Kafka 集群与 SelectDB Cloud 实现 Exactly_Once,具体原理如下:
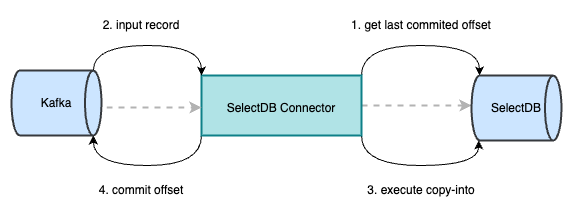
1.Kafka-Connector 在初始化时会主动向 SelectDB Cloud 获取当前所在 partition 已提交的 last_offset。
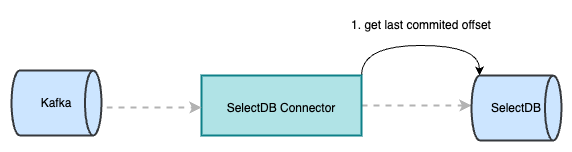
2.从 Kafka 消费数据,只有当前 record 的 offset 大于从 SelectDB Cloud 获取的 last_offset 后,才能被正常消费。当消费的 record 达到阈值,会生成一个以 last_offset 命名的临时文件,并将该文件上传至对象存储中。
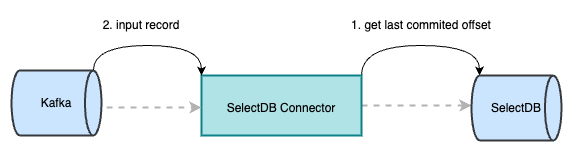
3.在 Kafka 调用执行 preCommit 时,会将对象存储中的数据由 copy-into 操作导入至 SelectDB 中,此时 SelectDB Cloud 会记录已提交成功的 last_offset。若此时 Kafka-Connector 执行 copy-into 失败,则会从 Kafka 中获取当前 partition 上一次执行成功的 offset,继续消费,从而保证数据不丢不重。
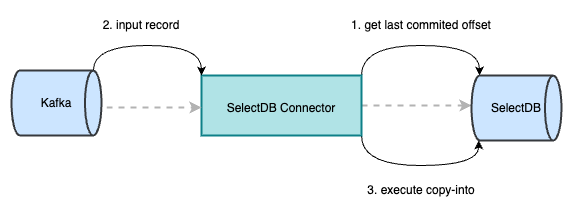
4.成功执行 copy-into 后,向 Kafka 提交记录当前 partition 已成功消费的 offset。若此时 Kafka-Connector 意外挂掉,重启该 task 或其他 task 在 Kafka 的分区自平衡机制下继续消费该 partition。通过初始化阶段可获取到 SelectDB 中已提交成功的 last_offset,继续消费,直至下一个 preCommit 阶段再向 Kafka 提交成功消费的 offset。
使用场景
Standalone 模式
在 Kafka config 目录下创建 connect-selectdb-sink.properties,并配置如下内容:
name=test-selectdb-sink
connector.class=com.selectdb.kafka.connector.SelectdbSinkConnector
topics=test_topic
selectdb.topic2table.map=test_topic:test_kafka_tbl
buffer.count.records=10000
buffer.flush.time=120
buffer.size.bytes=5000000
selectdb.url=xxx.cn-beijing.privatelink.aliyuncs.com
selectdb.http.port=1234
selectdb.query.port=1234
selectdb.user=admin
selectdb.password=***
selectdb.database=test_db
selectdb.cluster=test_cluster
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false启动Standalone
$KAFKA_HOME/bin/connect-standalone.sh -daemon $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-selectdb-sink.properties注意:一般不建议在生产环境中使用standalone模式
Distributed 模式
启动 Distributed
$KAFKA_HOME/bin/connect-distributed.sh -daemon $KAFKA_HOME/config/connect-distributed.properties增加 Connector
curl -i http://127.0.0.1:8083/connectors -H "Content-Type: application/json" -X POST -d '{
"name":"test-selectdb-sink-cluster",
"config":{
"connector.class":"com.selectdb.kafka.connector.SelectdbSinkConnector",
"tasks.max":"8",
"topics":"test_topic",
"selectdb.topic2table.map": "test_topic:test_kafka_tbl",
"buffer.count.records":"10000",
"buffer.flush.time":"120",
"buffer.size.bytes":"5000000",
"selectdb.url":"xx.cn-beijing.privatelink.aliyuncs.com",
"selectdb.user":"admin",
"selectdb.password":"***",
"selectdb.http.port":"1234",
"selectdb.query.port":"1234",
"selectdb.database":"test_db",
"selectdb.cluster":"test_cluster",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":"false",
"value.converter.schemas.enable":"false"
}
}'实践案例
环境准备
Kafka 单机环境,使用Kafka2.4版本:
#下载并解压
wget https://archive.apache.org/dist/kafka/2.4.0/kafka_2.12-2.4.0.tgz
tar -zxvf kafka_2.12-2.4.0.tgz
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
bin/kafka-server-start.sh -daemon config/server.properties快速同步 JSON 数据
1.配置SelectDB Sink
name=test-selectdb-sink
connector.class=com.selectdb.kafka.connector.SelectdbSinkConnector
topics=test_topic
selectdb.topic2table.map=test_topic:test_kafka_tbl
buffer.count.records=10000
buffer.flush.time=120
buffer.size.bytes=5000000
selectdb.url=xxx.cn-beijing.privatelink.aliyuncs.com
selectdb.http.port=1234
selectdb.query.port=1234
selectdb.user=admin
selectdb.password=***
selectdb.database=test_db
selectdb.cluster=test_cluster
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
#配置死信队列,可选
errors.tolerance=all
errors.deadletterqueue.topic.name=test_error
errors.deadletterqueue.context.headers.enable = true
errors.deadletterqueue.topic.replication.factor=12.启动 Kafka Connect
bin/connect-standalone.sh -daemon config/connect-standalone.properties config/selectdb-sink.properties使用 Debezium 数据同步 MySQL 数据到 SelectDB Cloud
在很多业务场景中,经常需要从业务数据库中实时同步数据,在这个时候就需要使用数据库的变更数据捕获(Change Data Capture,简称 CDC)机制。
而 Debezium 是基于 Kafka Connect 的 CDC 工具,可以对接 MySQL、PostgreSQL、SQL Server、Oracle、MongoDB 等多种数据库,把数据库的数据持续以统一的格式发送到 Kafka 的 Topic 中,以供下游 Sink 端进行实时消费。
这里以 MySQL 为例
1.下载Debezium
wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/1.5.4.Final/debezium-connector-mysql-1.5.4.Final-plugin.tar.gz
tar -zxvf debezium-connector-mysql-1.5.4.Final-plugin.tar.gz解压并将 jar 包放到 KAKFA_HOME/libs 目录下
2.配置Debezium Source
name=mysql-source
connector.class=io.debezium.connector.mysql.MySqlConnector
database.hostname=127.0.0.1
database.port=3306
database.user=root
database.password=123456
database.server.id=1
# kafka中的该client的唯一标识
database.server.name=test
# 需要同步的数据库,默认是同步所有数据库
database.include.list=db
database.history.kafka.bootstrap.servers=localhost:9092
# 用于存储数据库表结构变化的 Kafka topic
database.history.kafka.topic=dbhistory
transforms=unwrap
# 参考 https://debezium.io/documentation/reference/stable/transformations/event-flattening.html
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
# 记录删除事件
transforms.unwrap.delete.handling.mode=rewrite配置好之后,Kafka 中默认的 Topic 名称格式是 SERVER_NAME.DATABASE_NAME.TABLE_NAME
注:其他 Debezium 配置可参考 https://debezium.io/documentation/reference/1.5/connectors/mysql.html#mysql-connector-properties (opens in a new tab)
3.配置SelectDB Sink
name=test-selectdb-sink
connector.class=com.selectdb.kafka.connector.SelectdbSinkConnector
topics=test_topic
selectdb.topic2table.map=test_topic:test_kafka_tbl
buffer.count.records=10000
buffer.flush.time=120
buffer.size.bytes=5000000
selectdb.url=xxx.cn-beijing.privatelink.aliyuncs.com
selectdb.http.port=1234
selectdb.query.port=1234
selectdb.user=admin
selectdb.password=***
selectdb.database=test_db
selectdb.cluster=test_cluster
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
#配置死信队列,可选
errors.tolerance=all
errors.deadletterqueue.topic.name=test_error
errors.deadletterqueue.context.headers.enable = true
errors.deadletterqueue.topic.replication.factor=1同步到 SelectDB Cloud 时,需要先提前创建好库表。
4.启动 Kafka Connect
bin/connect-standalone.sh -daemon config/connect-standalone.properties config/mysql-source.properties config/selectdb-sink.properties启动后,可以观察日志 logs/connect.log 是否启动成功。
使用效果
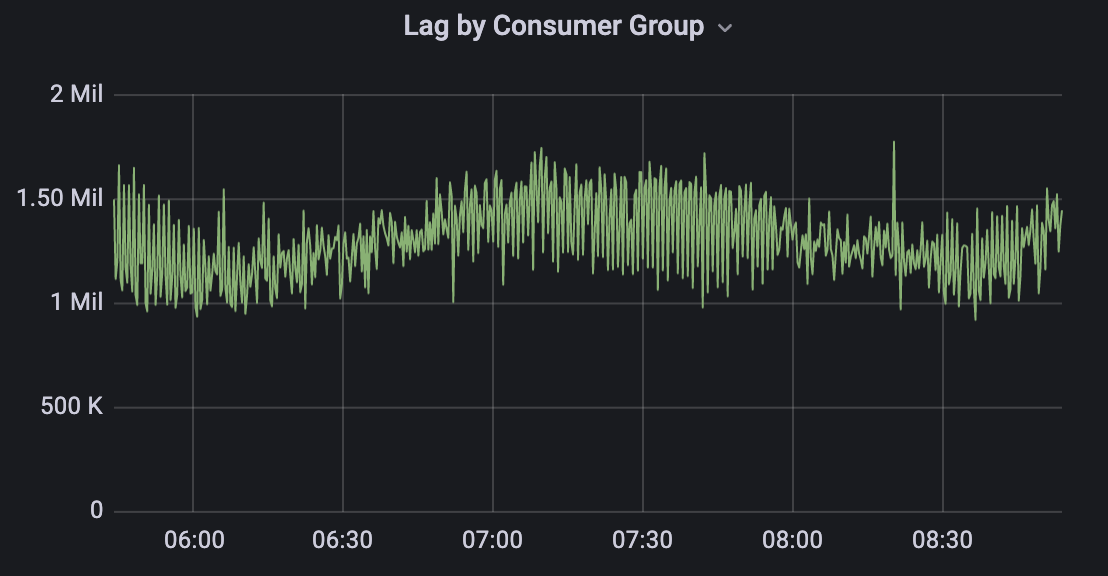
在调研的使用场景中,使用 Kafka 同步上游 JSON 数据。这里数据维持以每秒 10w 条的超高频导入,在 8c16g 的机器上,仅部署单节点 Kafka 集群,同时在 topic 中配置 20 个 partition,以 distributed 模式启动 connect。在实际处理过程中,topic 中的总体消息平均积压在 120w 条左右,单个 partition 积压 6w 条消息,表现相当优秀。
收益总结
整体来看,Kafka SelectDB Connector 打通了从 Kafka 直接导入数据至 SelectDB Cloud 的数据链路,降低了通过 Flink 作为中间数据同步组件的链路复杂度;通过 Exactly-Once 实现数据的一次性精确导入,确保了数据的准确性;通过以 Kafka 集群作为载体,在超高频的数据导入场景中,性能表现非常优秀。
SelectDB Cloud 丰富的大数据生态工具支持进一步降低了开发的门槛,结合其云原生下存算分离、弹性伸缩的 SaaS 化服务,能够帮助企业充分释放在技术研发上的精力,专注于业务场景效果提升,为企业开启简单、易用大数据分析之旅。