SelectDB Datax Writer 最佳实践
介绍
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP,等各种异构数据源之间稳定高效的数据同步功能。
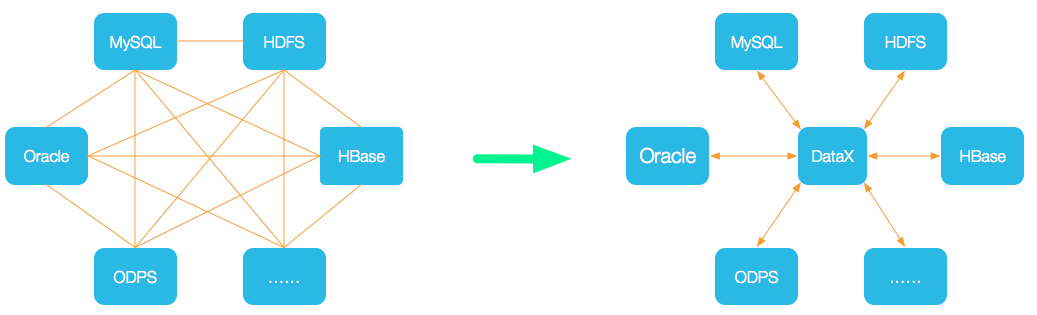
SelectDB Cloud 提供了datax-selectdb-writer 插件,可以将datax 支持的数据源同步到 selectDB Cloud 中
框架设计
主要分为三个部分:Reader,FrameWork,Writer
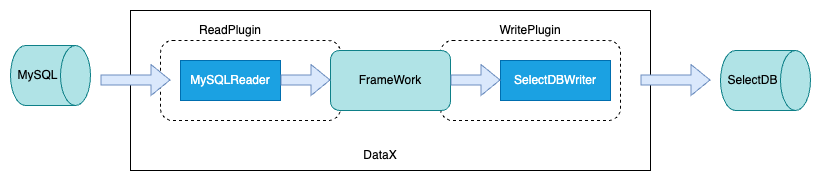
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
执行流程
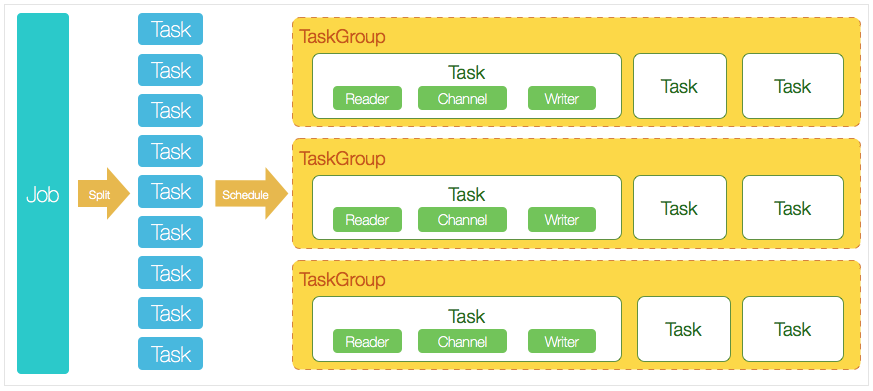
1.DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
2.DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
3.切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
4.每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
5.DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
SelectDB Writer介绍
快速介绍
该插件主要将 MySQL、Oracle 等数据库中的数据导入至 SELECTDB。该插件将数据转化为 CSV 或 JSON 格式并将其通过 copy into 方式批量导入至 SELECTDB。
实现原理
SelectDB Writer 通过调用selectdb upload api,返回一个重定向的S3地址,使用Http向S3地址发送字节流,设置参数达到要求时执行copy into
编译
1. 下载
git clone https://github.com/selectdb/datax-selectdb.git2. 运行 init-env.sh
这个脚本主要用于构建 DataX 开发环境,他主要进行了以下操作:
1 .将 DataX 代码库 clone 到本地。
2. 将 doriswriter/ 目录软链到 DataX/selectdbwriter 目录。
3. 在 DataX/pom.xml 文件中添加 <module>selectdbwriter</module> 模块。
4. 这个脚本执行后,开发者就可以进入 DataX/ 目录开始开发或编译了。因为做了软链,
所以任何对 DataX/doriswriter 目录中文件的修改,都会反映到 doriswriter/ 目录中,
方便开发者提交代码。3. 编译 selectdbwriter
3.1 编译整个 DataX 项目
mvn package assembly:assembly -Dmaven.test.skip=true
产出在 target/datax/datax/.
hdfsreader, hdfswriter and oscarwriter 这三个插件需要额外的jar包。如果你并不需要这些插件,可以在 DataX/pom.xml 中删除这些插件的模块。3.2 单独编译 doriswriter 插件
mvn clean install -pl plugin-rdbms-util,doriswriter -DskipTests3.3 编译错误
如遇到如下编译错误:
Could not find artifact com.alibaba.datax:datax-all:pom:0.0.1-SNAPSHOT ...可尝试以下方式解决:
- 下载 alibaba-datax-maven-m2-20210928.tar.gz (opens in a new tab)
- 解压后,将得到的
alibaba/datax/目录,拷贝到所使用的 maven 对应的.m2/repository/com/alibaba/下。 - 再次尝试编译。
示例
1.配置样例
这里是一份从Stream读取数据后导入至selectdb的配置文件。
{
"job":{
"content":[
{
"reader":{
"name":"streamreader",
"parameter":{
"column":[
{
"type":"string",
"random":"0,31"
},
{
"type":"string",
"random":"0,31"
},
{
"type":"string",
"random":"0,31"
},
{
"type":"string",
"random":"0,31"
},
{
"type":"long",
"random":"0,5"
},
{
"type":"string",
"random":"0,10"
},
{
"type":"string",
"random":"0,5"
},
{
"type":"string",
"random":"0,31"
},
{
"type":"string",
"random":"0,31"
},
{
"type":"string",
"random":"0,21"
},
{
"type":"string",
"random":"0,31"
},
{
"type":"long",
"random":"0,10"
},
{
"type":"long",
"random":"0,20"
},
{
"type":"date",
"random":"2022-01-01 12:00:00,2023-01-01 12:00:00"
},
{
"type":"long",
"random":"0,10"
},
{
"type":"date",
"random":"2022-01-01 12:00:00,2023-01-01 12:00:00"
},
{
"type":"string",
"random":"0,10"
},
{
"type":"long",
"random":"0,10"
},
{
"type":"date",
"random":"2022-01-01 12:00:00,2023-01-01 12:00:00"
},
{
"type":"long",
"random":"0,10"
},
{
"type":"date",
"random":"2022-01-01 12:00:00,2023-01-01 12:00:00"
},
{
"type":"long",
"random":"0,10"
},
{
"type":"date",
"random":"2022-01-01 12:00:00,2023-01-01 12:00:00"
},
{
"type":"long",
"random":"0,10"
},
{
"type":"date",
"random":"2022-01-01 12:00:00,2023-01-01 12:00:00"
},
{
"type":"string",
"random":"0,100"
},
{
"type":"string",
"random":"0,1"
},
{
"type":"long",
"random":"0,1"
},
{
"type":"string",
"random":"0,64"
},
{
"type":"string",
"random":"0,20"
},
{
"type":"string",
"random":"0,31"
},
{
"type":"long",
"random":"0,3"
},
{
"type":"long",
"random":"0,3"
},
{
"type":"long",
"random":"0,19"
},
{
"type":"date",
"random":"2022-01-01 12:00:00,2023-01-01 12:00:00"
},
{
"type":"string",
"random":"0,1"
}
],
"sliceRecordCount":10
}
},
"writer":{
"name":"selectdbwriter",
"parameter":{
"loadUrl":[
"xxx:47150"
],
"loadProps":{
"file.type":"json",
"file.strip_outer_array":"true"
},
"column":[
"id",
"table_id",
"table_no",
"table_name",
"table_status",
"no_disturb",
"dinner_type",
"member_id",
"reserve_bill_no",
"pre_order_no",
"queue_num",
"person_num",
"open_time",
"open_time_format",
"order_time",
"order_time_format",
"table_bill_id",
"offer_time",
"offer_time_format",
"confirm_bill_time",
"confirm_bill_time_format",
"bill_time",
"bill_time_format",
"clear_time",
"clear_time_format",
"table_message",
"bill_close",
"table_type",
"pad_mac",
"company_id",
"shop_id",
"is_sync",
"table_split_no",
"ts",
"ts_format",
"dr"
],
"username":"admin",
"password":"SelectDB2022",
"postSql":[
],
"preSql":[
],
"connection":[
{
"jdbcUrl":"jdbc:mysql://xxx:34142/cl_test",
"table":[
"ods_pos_pro_table_dynamic_delta_v4"
],
"selectedDatabase":"cl_test"
}
],
"maxBatchRows":1000000,
"maxBatchByteSize":536870912000
}
}
}
],
"setting":{
"errorLimit":{
"percentage":0.02,
"record":0
},
"speed":{
"channel":5
}
}
}
}2.执行任务
python $DATAX_HOME/datax.py ../xx.json3.参数说明
**jdbcUrl**
- 描述:selectdb 的 JDBC 连接串,用户执行 preSql 或 postSQL。
- 必选:是
- 默认值:无
* **loadUrl**
- 描述:作为 selecdb 的连接目标。格式为 "ip:port"。其中 IP 是 selectdb的private-link,port 是selectdb 集群的 http_port
- 必选:是
- 默认值:无
* **username**
- 描述:访问selectdb数据库的用户名
- 必选:是
- 默认值:无
* **password**
- 描述:访问selectdb数据库的密码
- 必选:否
- 默认值:空
* **connection.selectedDatabase**
- 描述:需要写入的selectdb数据库名称。
- 必选:是
- 默认值:无
* **connection.table**
- 描述:需要写入的selectdb表名称。
- 必选:是
- 默认值:无
* **column**
- 描述:目的表**需要写入数据**的字段,这些字段将作为生成的 Json 数据的字段名。字段之间用英文逗号分隔。例如: "column": ["id","name","age"]。
- 必选:是
- 默认值:否
* **preSql**
- 描述:写入数据到目的表前,会先执行这里的标准语句。
- 必选:否
- 默认值:无
* **postSql**
- 描述:写入数据到目的表后,会执行这里的标准语句。
- 必选:否
- 默认值:无
* **maxBatchRows**
- 描述:每批次导入数据的最大行数。和 **batchSize** 共同控制每批次的导入数量。每批次数据达到两个阈值之一,即开始导入这一批次的数据。
- 必选:否
- 默认值:500000
* **batchSize**
- 描述:每批次导入数据的最大数据量。和 **maxBatchRows** 共同控制每批次的导入数量。每批次数据达到两个阈值之一,即开始导入这一批次的数据。
- 必选:否
- 默认值:90M
* **maxRetries**
- 描述:每批次导入数据失败后的重试次数。
- 必选:否
- 默认值:3
* **labelPrefix**
- 描述:每批次上传文件的 label 前缀。最终的 label 将有 `labelPrefix + UUID` 组成全局唯一的 label,确保数据不会重复导入
- 必选:否
- 默认值:`datax_selectdb_writer_`
* **loadProps**
- 描述:COPY INOT 的请求参数
这里包括导入的数据格式:file.type等,导入数据格式默认我们使用csv,支持JSON,具体可以参照下面类型转换部分
- 必选:否
- 默认值:无
* **clusterName**
- 描述:selectdb could 集群名称
- 必选:否
- 默认值:无
* **flushQueueLength**
- 描述:队列长度
- 必选:否
- 默认值:1
* **flushInterval**
- 描述:数据写入批次的时间间隔,如果maxBatchRows 和 batchSize 参数设置的有很大,那么很可能达不到你这设置的数据量大小,会执行导入。
- 必选:否
- 默认值:30000ms类型转化
默认传入的数据均会被转为字符串,并以`\t`作为列分隔符,`\n`作为行分隔符,组成`csv`文件进行Selectdb导入操作。
默认是csv格式导入,如需更改列分隔符, 则正确配置 `loadProps` 即可:
"loadProps": {
"file.column_separator": "\\x01",
"file.line_delimiter": "\\x02"
}如需更改导入格式为`json`, 则正确配置 `loadProps` 即可:
"loadProps": {
"file.type": "json",
"file.strip_outer_array": true
}