Spark SelectDB Connector 介绍
什么是 Spark SelectDB Connector?
Spark SelectDB Connector 作为 SelectDB Cloud 上大数据量的导入方式之一,可以利用 Spark天然的分布式计算优势将数据导入到 SelectDB Cloud 中。具体来讲,Spark SelectDB Connector 支持将其他数据源(PostgreSQL, HDFS, S3等)的数据通过 Spark 计算引擎后同步到 SelectDB Cloud 的数据表中。
利用 Spark SelectDB Connector,开发者能够使用 Spark 将上游数据源读取到 DataFrame 中,然后使用 Spark SelectDB Connector 将大规模数据导入到SelectDB Cloud 数据仓库的表中;同时,开发者可以使用 Spark 的 JDBC 的方式来读取 SelectDB Cloud 表中的数据。
基础架构
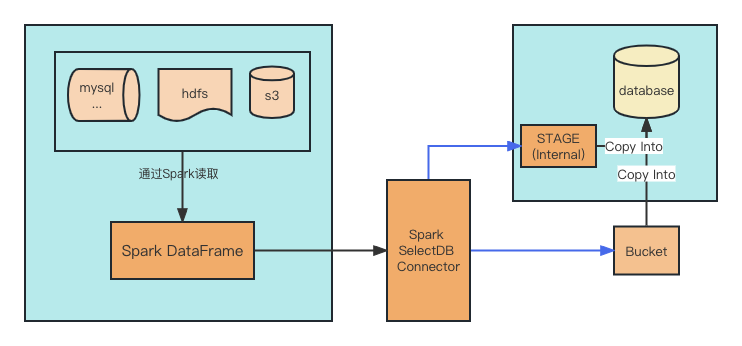
在整个架构中,通常 Spark SelectDB Connector 作为外部数据写入到 SelectDB Cloud 的桥梁,优化了传统地使用 JDBC 这种低性能的连接写入方式,以其分布式、高效的特性丰富了整个数据链路。
工作原理
Spark Selectdb Connector 底层实现依赖于 SelectDB Cloud 的 stage 导入方式,当前支持两种Stage 导入方式:
- 通过创建对象存储上的 stage 来进行批量数据拉取导入,这个主要适合大批量数据导入,使用前提是用户有自己的对象存储及其相关密钥;
- 基于内置的 stage 的推送导入,这个主要是和小批量推送,使用较简单;
对于第一种导入方式,依赖于用户自己的对象存储,首先需要在 SelectDB Cloud 中创建 External Stage,然后将创建的 External Stage 的访问权限给用户,用户可以将需要导入的数据存储已经配置好的External Stage的存储中,通过 Spark 调用 SelectDB Cloud 的 copy into 接口(/copyinto)将对象存储的数据导入SelectDB Cloud的表中。
对于第二种导入方式,主要依赖于 SelectDB Cloud 提供的内置对象存储,Spark 通过调用SelectDB Cloud的upload接口(/copy/upload)会返回一个重定向的对象存储地址,使用 http 的方式向S3地址发送字节流,待数据上传完成之后在调用 SelectDB Cloud 的 copy into 接口(/copyinto)将对象存储的数据导入 SelectDB Cloud 的表中。
使用教程
下载方式
我们已经预编译了三个包供大家来直接下载,详细版本以及下载地址见下表:
| Connector | Runtime Jar |
|---|---|
| 2.3-2.11-1.0.1 | spark-selectdb-connector-2.3_2.11-1.0.1 (opens in a new tab) |
| 3.1-2.12-1.0.1 | spark-selectdb-connector-3.1_2.12-1.0.1 (opens in a new tab) |
| 3.2-2.12-1.0.1 | spark-selectdb-connector-3.2_2.12-1.0.1 (opens in a new tab) |
注意:
- 所有的jar包是通过 java 8 来编译的;
- 如有其他版本需求可通过 SelectDB 官网的联系方式 (opens in a new tab)来联系我们;
本地开发
一般我们本地开发通过 maven 引入依赖的方式将 Spark SelectDB Connector 的包引入到我们的项目中,在 maven 中使用以下方式添加依赖。
<dependency>
<groupId>com.selectdb.spark</groupId>
<artifactId>spark-selectdb-connector-3.1_2.12</artifactId>
<version>1.0.1</version>
</dependency>Spark Standalone & Cluster 方式
如果使用 Spark Standalone 或者 Spark Cluster 的方式运行我们的 Spark 程序,只需要将下载的jar 放到 Spark 安装目录的 jars 目录下即可。
如果多节点Spark,需要在每个 Spark 节点的jars目录下放一份 Spark SelectDB Connector 的jar包。
Spark On Yarn
Yarn集群模式运行的Spark,则将此文件放入预部署包中。例如将 spark-selectdb-connector-2.3.4-2.11-1.0.-SNAPSHOT.jar 上传到 hdfs并在spark.yarn.jars参数上添加 hdfs上的Jar包路径
-
上传
spark-selectdb-connector-2.3.4-2.11-1.0-SNAPSHOT.jar到hdfs。hdfs dfs -mkdir /spark-jars/ hdfs dfs -put /your_local_path/spark-selectdb-connector-2.3.4-2.11-1.0-SNAPSHOT.jar /spark-jars/
-
在集群中添加
spark-selectdb-connector-2.3.4-2.11-1.0-SNAPSHOT.jar依赖。spark.yarn.jars=hdfs:///spark-jars/doris-spark-connector-3.1.2-2.12-1.0.0.jar
使用场景
通过 sparksql 的方式写入
val selectdbHttpPort = "127.0.0.1:47968"
val selectdbJdbc = "jdbc:mysql://127.0.0.1:18836/test"
val selectdbUser = "admin"
val selectdbPwd = "selectdb2022"
val selectdbTable = "test.test_order"
CREATE TEMPORARY VIEW test_order
USING selectdb
OPTIONS(
"table.identifier"="test.test_order",
"jdbc.url"="${selectdbJdbc}",
"http.port"="${selectdbHttpPort}",
"user"="${selectdbUser}",
"password"="${selectdbPwd}",
"sink.properties.file.type"="json"
);
insert into test_order select order_id,order_amount,order_status from tmp_tb ;通过 DataFrame 方式写入
val spark = SparkSession.builder().master("local[1]").getOrCreate()
val df = spark.createDataFrame(Seq(
("1", 100, "待付款"),
("2", 200, null),
("3", 300, "已收货")
)).toDF("order_id", "order_amount", "order_status")
df.write
.format("selectdb")
.option("selectdb.http.port", selectdbHttpPort)
.option("selectdb.table.identifier", selectdbTable)
.option("user", selectdbUser)
.option("password", selectdbPwd)
.option("sink.batch.size", 4)
.option("sink.max-retries", 2)
.option("sink.properties.file.column_separator", "\t")
.option("sink.properties.file.line_delimiter", "\n")
.save()具体案例
本章节我们以一个例子来演示如何使用 Spark SelectDB Connector,演示的环境各版本如下:
| Java | Spark | Scala | SelectDB Cloud | |
|---|---|---|---|---|
| 版本 | 1.8 | 3.1.2 | 2.12 | 2.2.1 |
在开始导入之前,我们需要做几项准备工作:
- Spark 环境构建,从官网下载 Spark 安装包,本次演示所用 Spark 安装包 spark-3.1.2-bin-hadoop3.2.tgz;
- 构造导入的数据,此次我们只是测试,构造4条数据来完成导入;
- Selectdb Cloud 创建仓库以及集群,设置admin 的密码,开通公网连接,将我们 Spark 环境的公网ip配置到ip白名单中;
我们先来看构建我们的 Spark 环境,下载spark-3.1.2-bin-hadoop3.2.tgz安装包,解压安装包;
wget https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
tar xvzf spark-3.1.2-bin-hadoop3.2.tgz将spark-selectdb-connector-3.1.2_2.12-1.0-SNAPSHOT.jar放到/opt/selectdb/spark-3.1.2-bin-hadoop3.2/jars目录下

导入的原始数据如下:
1,100,已下单
2,200,已付款
3,300,已发货
4,400,已收货SelectDB Cloud 中创建数据表:
CREATE TABLE `spark_selectdb_connector` (
`order_id` varchar(30) NULL,
`order_amount` int(11) NULL,
`order_status` varchar(30) NULL
) ENGINE=OLAP
DUPLICATE KEY(`order_id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`order_id`) BUCKETS 10
PROPERTIES (
"persistent" = "false"
); 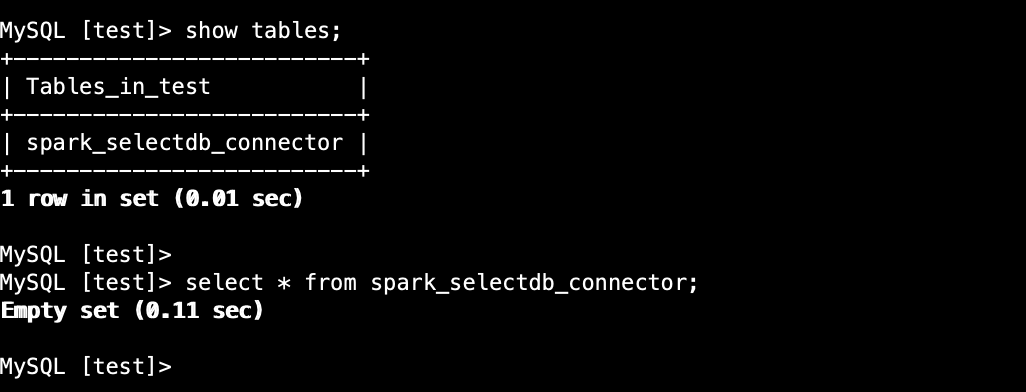
我们以 spark-shell 的方式将我们的测试数据导入到 SelectDB Cloud 的数据表中:
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
val session = SparkSession.builder().master("local[*]").getOrCreate()
val scam = StructType(StructField("order_id",StringType)::StructField("order_amount",IntegerType)::StructField("order_status",StringType)::Nil)
val df = spark.read.schema(scam).csv("file:///opt/selectdb/data/test.txt")
df.write.format("selectdb")
.option("selectdb.http.port", "81.70.4.52:36511")
.option("selectdb.table.identifier", "test.spark_selectdb_connector")
.option("user", "admin")
.option("password", "Admin12345")
.option("sink.batch.size", 4)
.option("sink.max-retries", 2)
.save()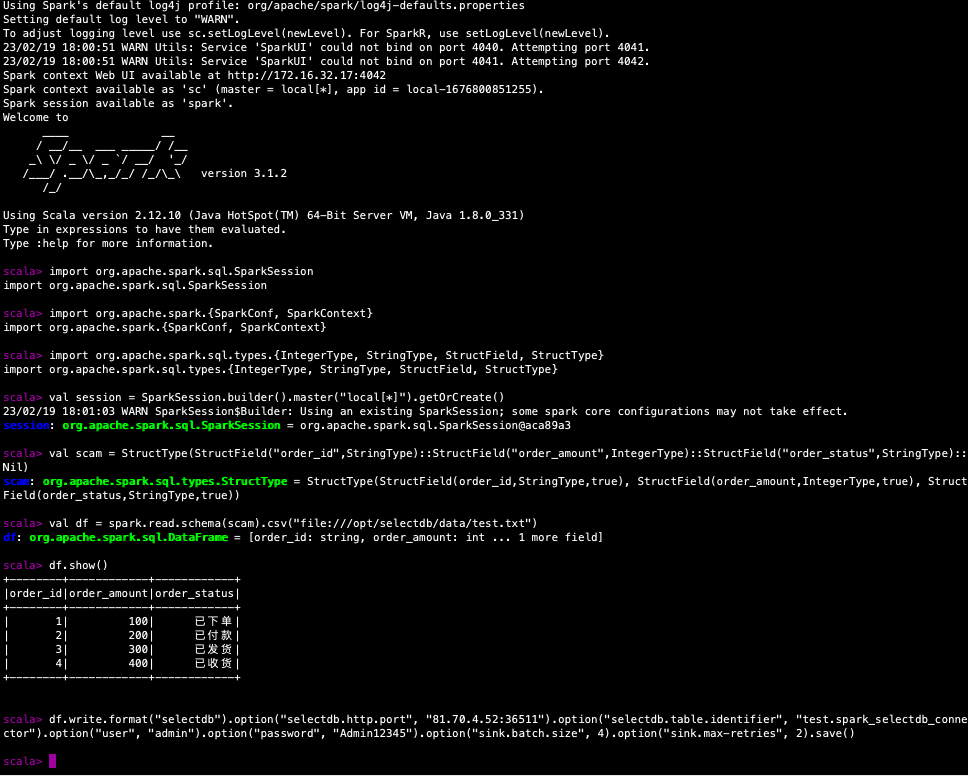
Spark 任务执行完成后,我们可以通过 mysql-client 连接 Selectdb Cloud,查看我们通过导入的数据。
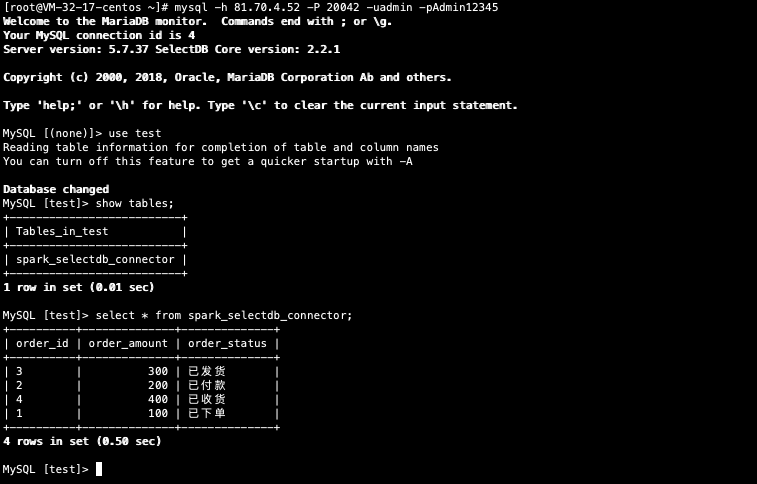
至此,我们通过 Spark SelectDB Connector 导入数据的案例就结束了。
总结
本篇我们从Spark SelectDB Connector的原理以及实践等各方面做了详细介绍,大家有以下几种场景需求的情况可以使用这种连接器:
- 以 Spark 为计算引擎构建的技术架构体系,减少其他组件引入的成本;
- 大规模数据 ETL 离线写入SelectDB Cloud,利用 Spark 分布式计算的特性,降低SelectDB Cloud集群资源消耗成本;
Spark SelectDB Connector 以 Spark 这个大数据计算的优秀组件作为核心,实现了利用 Spark 将外部数据源的大数据量同步到 SelectDB Cloud,便于我们实现大批量数据的快速同步,继而利用 SelectDB Cloud 为基石构建新一代的云原生数据仓库,结合 SelectDB Cloud 强大的分析计算性能,能够为企业带来业务便捷性以及增效将本的目标。